Streaming 101
스트리밍 데이터 처리는 다음과 같은 장점을 가지고 있다.
- 배치 시스템에 비해 낮은 레이턴시를 보장할 수 있는 방법이다.
- 무한한 크기의 데이터를 처리하는 시스템을 통해 거대하고 Unbound 된 데이터를 처리할 수 있다.
- 데이터를 처리 워크로드를 분산시킬 수 있다.
스트리밍 시스템은 무한한 데이터를 처리할 수 있도록 디자인된 데이터 처리 엔진이다.
데이터를 분류하는 기준은 크게 두 가지가 존재하는데, Cardinality와 Constitution이다.
Cardinality
데이터의 크기를 의미한다. Cardinality를 기준으로 데이터를 분류하면 Bounded Data와 Unbounded Data로 분류할 수 있다.
- Bounded Data: 유한한 크기를 가진 데이터
- Unbounded Data: (이론적으로) 무한한 크기를 가진 데이터
Constitution
데이터와 상호작용할 수 있는 방법을 의미한다.
- Table: 특정 시점에서의 데이터를 바라보는 관점이다.
- Stream: 시간에 걸쳐 변화하는 데이터를 바라보는 관점이다.
Event time vs Processing time
Unbound Data 처리를 위해서는 Time domain에 대해 이해하여야 한다. Time domain은 두가지가 존재한다.
- Event time: 이벤트가 실제로 발생한 시간
- Processing time: 시스템에서 이벤트가 관측된 시간
이상적으로는 Event가 발생하자마자 시스템에서 즉시 처리되어야 하므로 Event time과 Processing time이 같다.
하지만 실제로는 입력 데이터(모바일 환경에서는 네트워크 등의 상황 때문에 데이터 전송이 늦어질 수 있음), 실행 엔진(엔진에 따라 데이터를 처리하는 시점이 다름), 하드웨어(여러 Application이 Hardware를 Share하는 형태이기 때문에 지연이 발생할 수 있음)의 특성 때문에 Event time과 Processing time 사이에 Skew가 발생한다.
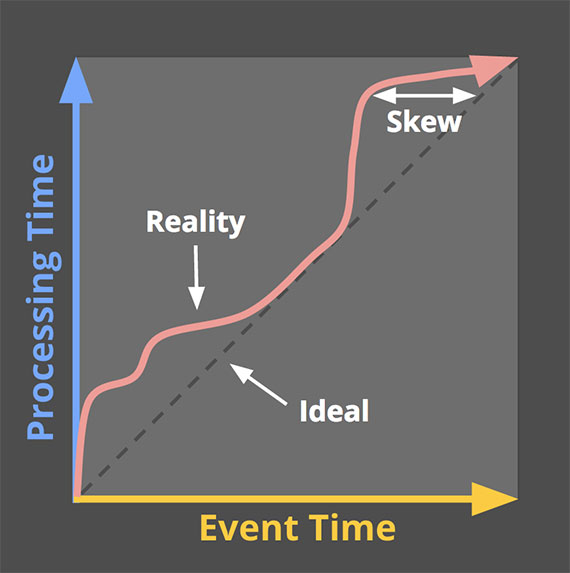
이상적인 상황에서는 Event가 발생함과 동시에 처리되기 때문에 그래프에 ideal과 같은 곡선이 그려져야 한다.
그러나 여러가지 이유로 인해 데이터의 처리가 늦어지기 때문에 Event time과 Processing time 사이에 갭이 발생하게 되고, 이를 Event time Skew(Processing time lag)이라고 표현한다.
Processing time 기준으로 데이터를 처리하게 되면 Event time skew 때문에 부정확한 결과가 만들어질 수 있다.
그러나 Event time 기준으로 데이터를 처리하는 것 또한 문제가 발생할 수 있다. 언제 처리해야 모든 Event가 발생했는지 판단하기 어렵기 때문이다.(ex. 모바일 환경에서 비행기 모드로 진입 후 발송되지 않았던 데이터가 하루 뒤 시스템에 들어오게 된다면?)
Data processing patterns
Bounded Data
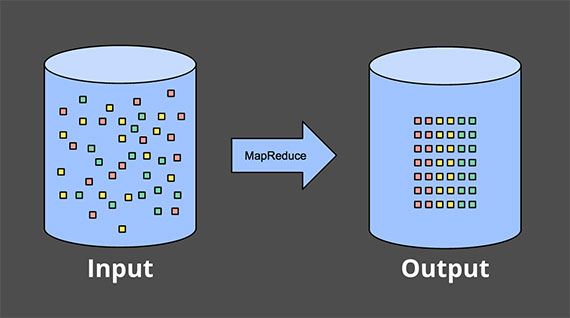
배치 시스템에서 데이터를 처리하는 일반적인 방식. 저장되어 있는 데이터를 읽어 결과물을 출력한다.
Unbounded Data: Batch
배치 시스템은 명시적으로 Unbounded Data를 처리할 수 있도록 디자인되어 있지는 않지만, Unbounded Data를 Bound Data로 쪼개어 처리하는 방식으로 Unbounded Data를 처리할 수 있다.
Fixed windows
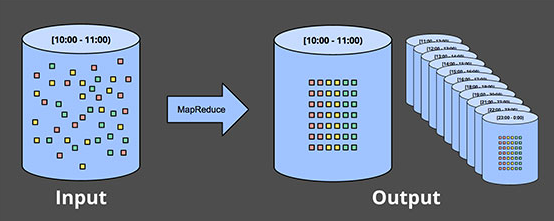
입력 데이터를 고정된 Window로 쪼개어 반복적으로 처리한다. 예를 들어 로그 데이터의 경우 시간 단위의 디렉토리 혹은 파일로 저장하고 특정 시간에 한번에 읽어 처리할 수 있다.
물론 이러한 방식도 정말 늦게 들어오는 데이터(Late data)를 처리한다거나, 시간 단위로 데이터를 저장할 수 없을 경우 등의 문제점이 있을 수 있다.
Sessions
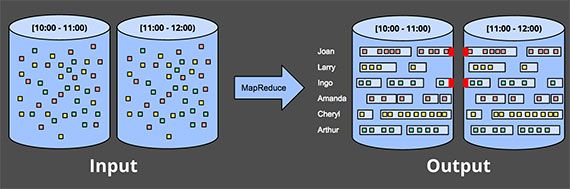 Session은 일반적으로 사용자의 활동 시간(시작 ~ 종료)를 의미한다. 세션의 길이는 가변적이기 때문에, Fixed window로 처리할 경우 위의 붉은 구간과 같이 잘릴 수 있다.
Session은 일반적으로 사용자의 활동 시간(시작 ~ 종료)를 의미한다. 세션의 길이는 가변적이기 때문에, Fixed window로 처리할 경우 위의 붉은 구간과 같이 잘릴 수 있다.
그렇기 때문에 Window의 크기를 크게 잡거나(아무리 크게 잡아도 잘릴 수 있음) 이전 결과를 참조(처리 로직의 복잡도가 높아질 수 있음)하여 처리하게 된다.
Unbounded Data: Streaming
배치 시스템이 Ad-hoc하게 Unbounded Data를 처리하는 것과 달리 스트리밍 시스템은 애초에 Unbounded Data를 처리하도록 설계되었다.
그러나 스트리밍 시스템에서도 Unbounded Data를 처리하는데 아래와 같은 장애물이 있다.
- 데이터들이 Event time 순서에 맞게 순차적으로 들어오지 않기 때문에, 데이터를 처리하는 파이프라인 내에서 시간 기준의 정렬이 필요하다.
- Event time skew가 발생하기 때문에 Event가 발생한 시점부터 상수 시간 내에 항상 해당 Event를 볼 수 있다고 단정할 수 없다.
이러한 특성을 가지는 데이터를 다루는 데에 필요한 접근은 Time-agnostic, Approximation, Windowing by processing time, Windowing by event time 으로 분류할 수 있다.
Time-agnostic
Time-agnostic 처리는 시간과 관계 없는 데이터를 처리하는데에 사용된다. 이러한 데이터를 처리 할 때는 스트리밍 시스템이 단순히 데이터를 전달하는 역할 밖에 하지 않는다.
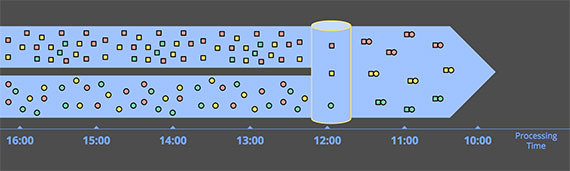
Filtering
가장 기본적인 Time-agnostic 연산 중 하나이다. 하나의 데이터 요소를 데이터의 특성으로 걸러내는 방식이기 때문에, 다른 데이터와 연관이 없다. 결과적으로 데이터가 Unbounded, Unordeded, Event time skew 되더라도 아무런 상관이 없다.
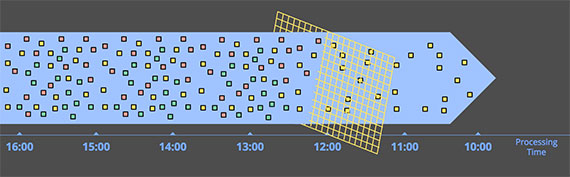
Inner joins
두 개의 데이터 스트림이 존재할 때, 하나의 데이터 스트림을 특정 시간 동안 모아놓고(Buffering), 다른 하나의 데이터 스트림이 들어오면 버퍼링 된 데이터와 Join을 수행하는 방식이다.
Windowing
 Windowing은 데이터에 대한 처리를 수행하기 위해 데이터를 유한한 크기로 분할하는 것이다. Windowing에는 Fixed windows, Sliding windows, Sessions와 같은 방법이 존재한다.
Windowing은 데이터에 대한 처리를 수행하기 위해 데이터를 유한한 크기로 분할하는 것이다. Windowing에는 Fixed windows, Sliding windows, Sessions와 같은 방법이 존재한다.
Fixed windows(aka tumbling windows)
Fixed windows는 고정된 길이의 Window로 데이터를 분할하는 방식이다.
Sliding windows(aka hopping windows)
Sliding windows는 고정된 길이와 고정된 주기로 정의할 수 있다.
- 주기가 길이보다 짧은 경우 Window가 Overlap 된다.
- 주기와 길이가 동일한 경우 Fixed windows가 된다.
- 주기가 길이보다 긴 경우 데이터를 Sampling하는 효과가 발생한다.
Sessions
Session은 유동적인 Window 형태를 가진다.
Time domain 기준으로 Windowing 할 수도 있다.
Windowing by processing time
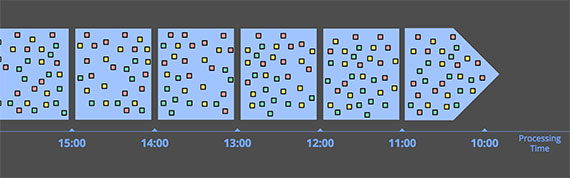
일정한 Processing time 동안 입력 데이터를 버퍼링하여 처리하는 방식이다.
이 방식은 시스템에 입력되어 처리되는 시간(Processing time)만 고려하면 되기 때문에(다른 말로 Event time을 전혀 신경쓰지 않기 때문에), 데이터의 지연이나 시간에 의한 섞임이라는 개념이 존재할 수 없다(는 장점이 있다).
그러나 Event time에 종속적인 분석은 불가능하다.(예를 들어 사용자가 언제, 어떤 순서로 어떤 행위를 수행했는지에 대한 분석 등)
Windowing by event time
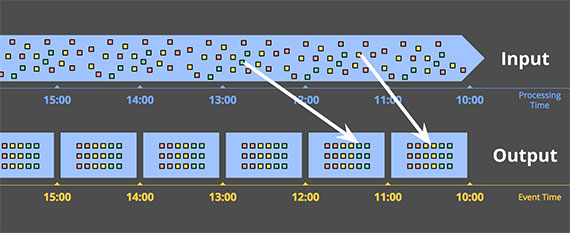
Event time을 반영하여 입력 데이터를 쪼개서 처리하는 방식이다.
데이터가 Input 축에서는 Event time에 관계 없이 Processing time에 아무렇게나 분포되어 있지만, Output 축으로 이동할 때(데이터가 처리된 이후)는 Event time에 맞게 재배열된 후 처리된다.
Event time 기준으로 데이터를 처리하게 되면 정확도는 Processing time 기준으로 처리하는 것보다 정확도가 높지만, 다음과 같은 단점을 가지게 된다.
- Buffering: Windowing by processing time 방식과는 달리 Event의 지연 전송 등을 고려하기 때문에 더 많은 데이터를 버퍼링해야 한다.
- Completeness: 데이터의 지연 전송 등으로 언제 마지막 데이터가 들어오는지 알 수 없기 때문에, Window의 끝을 정하기가 어렵다. 대부분의 Framework에서는 Heuristic 방식을 사용하여 Window의 끝을 판단한다.