Streaming 102
Streaming 101에서 등장한 개념 이외에도 Trigger, Watermark, Accumulation이라는 개념이 등장한다.
Trigger
Window의 Output을 언제 내보낼지 결정하는 동작을 의미한다.
단순히 한번만 Window의 결과를 출력하지 않고 Window의 결과물이 달라짐에 따라 여러 번 결과를 출력하는 것도 가능하다. 이렇게 동일한 Window의 결과를 여러 번 출력하는 것은 Late data에 의해 변경되는 Window의 결과를 출력하는데 효과적이다.
Watermark
Watermark는 Event time에 따른 입력 데이터의 수신 완료를 의미한다.
Watermark X는 X 시간 이전에 발생한 모든 Event가 시스템에서 관측되었다는 의미이다.
Accumulation
Accumulation은 동일한 Window에서 관측되는 여러 결과들 사이의 관계이다. Window의 출력은 동일한 Window의 이전 결과와 독립적일 수도 있고, 누적된 값일 수도 있다.
예를 들어 입력 데이터가 다음과 같이 세 번에 걸쳐 들어오고(Micro batch), 이 데이터들의 합을 출력하는 어플리케이션이 있다고 가정해보자.
- 1, 1, 1, 1, 1
- 1, 1, 1
- 1, 1, 1, 1
각 방식에 따라 아래와 같이 출력된다.
이전 결과에 독립적인 경우
| Event time | Processing time | 결과 |
|---|---|---|
| [2019-06-27 22:00:00, 2019-06-27 22:01:00] | 2019-06-27 22:02:01 | 5 |
| [2019-06-27 22:00:00, 2019-06-27 22:01:00] | 2019-06-27 22:03:10 | 3 |
| [2019-06-27 22:00:00, 2019-06-27 22:01:00] | 2019-06-27 22:09:15 | 4 |
이전 결과에 의존적인 경우(여기서는 누적)
| Event time | Processing time | 결과 |
|---|---|---|
| [2019-06-27 22:00:00, 2019-06-27 22:01:00] | 2019-06-27 22:02:01 | 5 |
| [2019-06-27 22:00:00, 2019-06-27 22:01:00] | 2019-06-27 22:03:10 | 8 |
| [2019-06-27 22:00:00, 2019-06-27 22:01:00] | 2019-06-27 22:09:15 | 12 |
Going Streaming: When and How
결과는 (Processing time에서) 언제 집계되어 출력되는가? - Trigger
Window의 결과가 언제 집계되어 출력되는지는 Trigger가 결정한다. Trigger에는 크게 두 가지 방식이 존재한다.
Repeated update trigger
Window의 결과가 바뀔 때마다 혹은 특정 Processing time 주기마다 결과를 계산하여 출력한다.
Repeated update trigger의 주기는 Latency와 Cost의 밸런스를 찾아서 맞추어야 한다. 예를 들어 주기가 짧을 경우 Latency는 짧아질 수 있지만 Cost(투입되는 컴퓨팅 자원 등)가 커질 수 있다.
Completeness triggers
Completeness trigger의 경우 Window의 모든 입력이 들어왔다고 생각될 때 Window를 처리하여 결과를 출력하는 방식이다. 일반적으로 우리가 사용하는 배치 방식의 경우, 예를 들어 일 배치인 경우 새벽 1시 이후에는 이전 일자 데이터가 모두 적재되었다고 가정하고 작업을 수행한다.
스트리밍 시스템에서는 일반적으로 Repeated update trigger를 사용한다.
Repeated update trigger에도 결과를 출력하는 방식이 여러 가지 존재한다.
Triggering repeatedly with every record
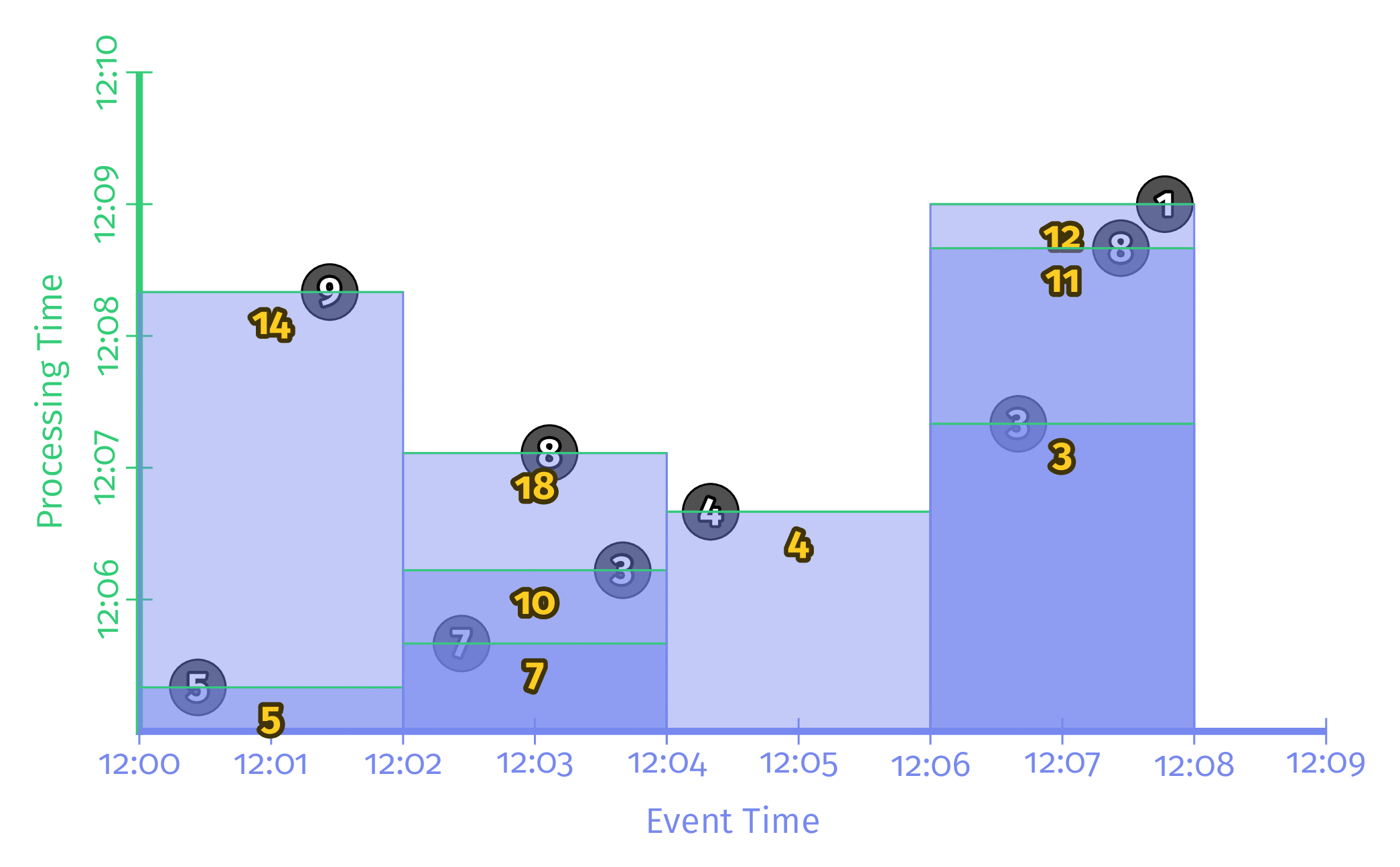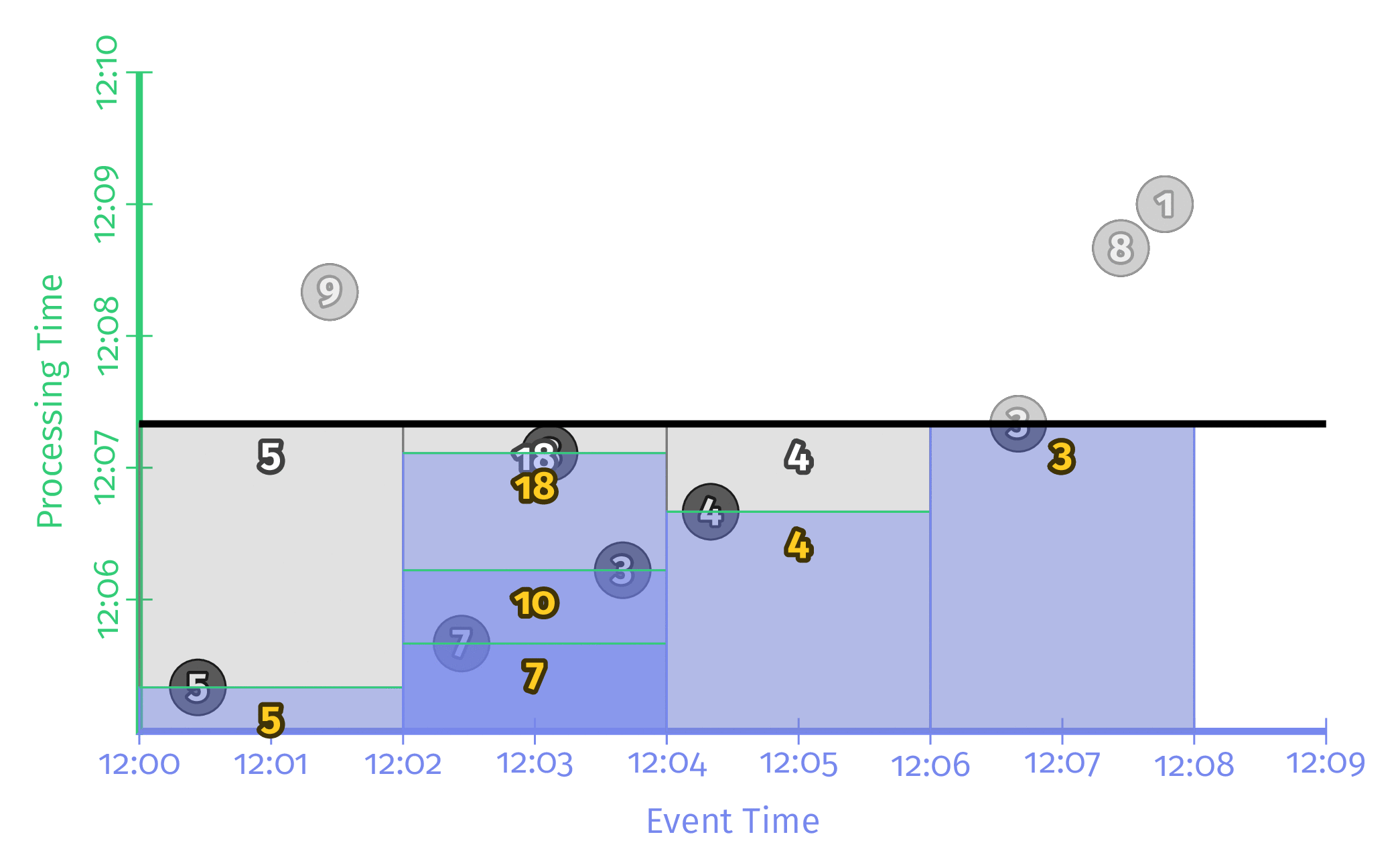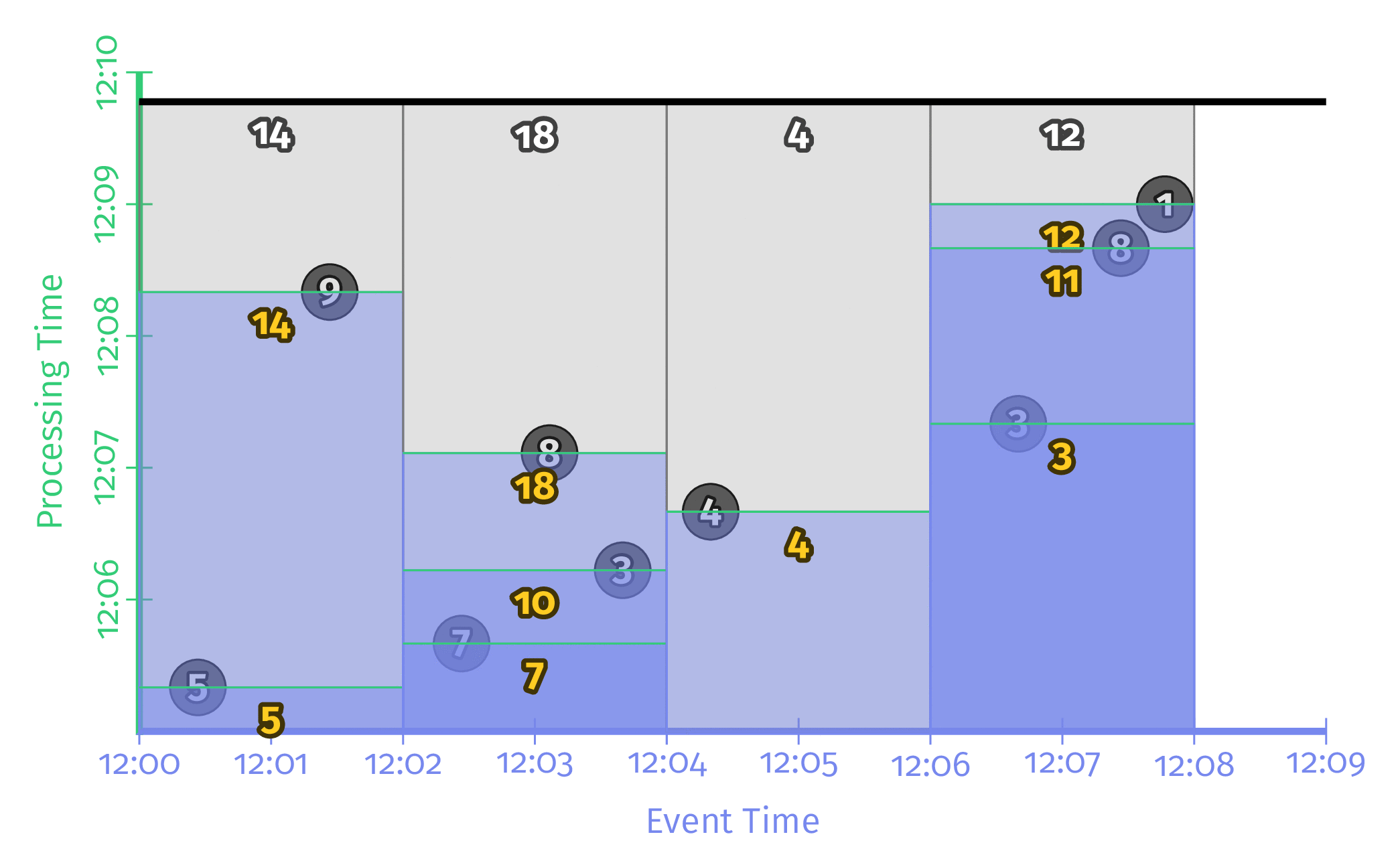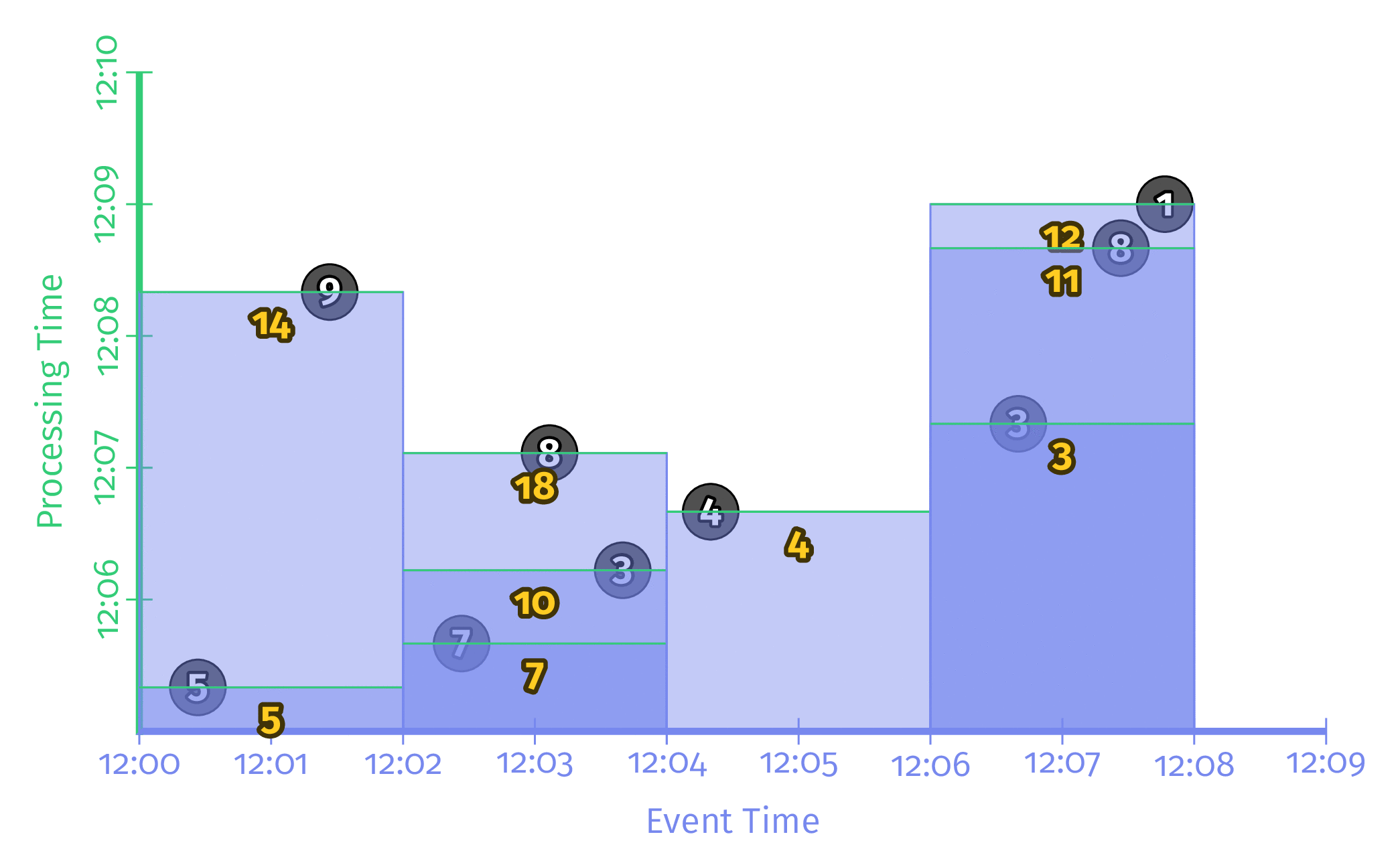
입력이 한건 들어올 때마다 해당 Window의 값을 계산하여 결과를 출력하는 방식이다. 높은 Latency를 가지긴 하지만 입력 데이터가 매우 많이 빠르게 들어올 경우 결과 데이터 또한 매우 빠르게 바뀌어 보기 힘들다는 단점이 존재한다.
Triggering repeatedly with aligned delays
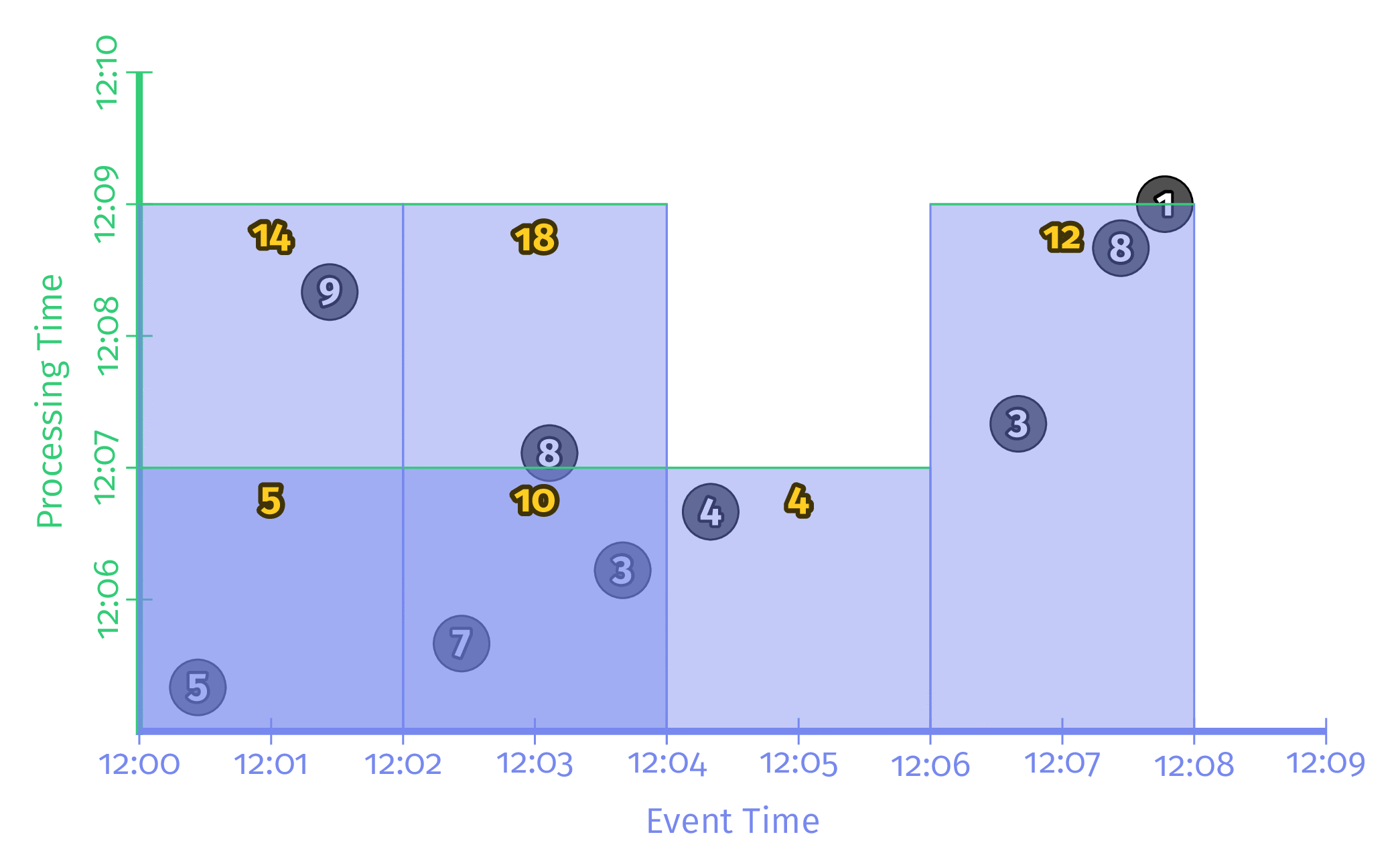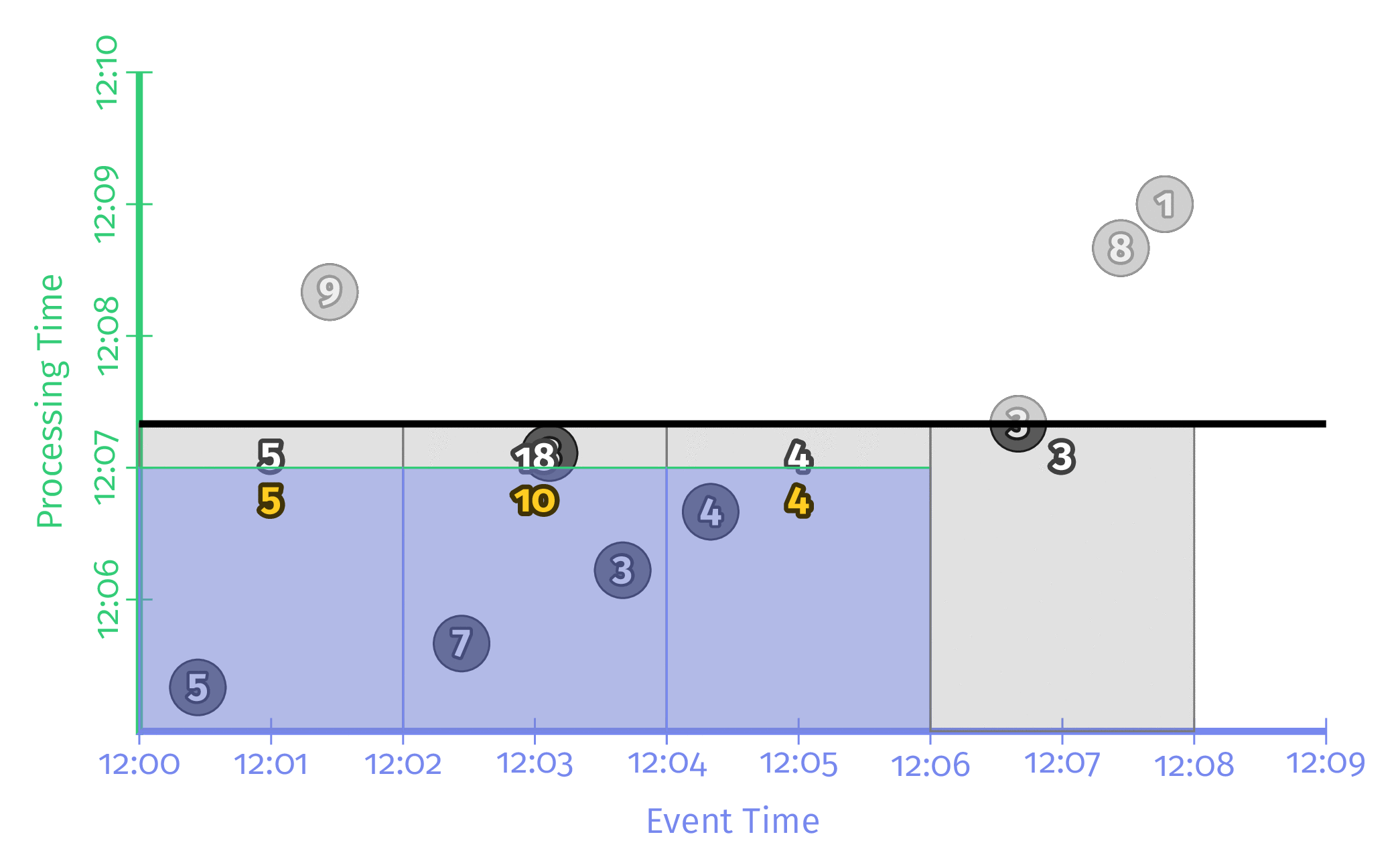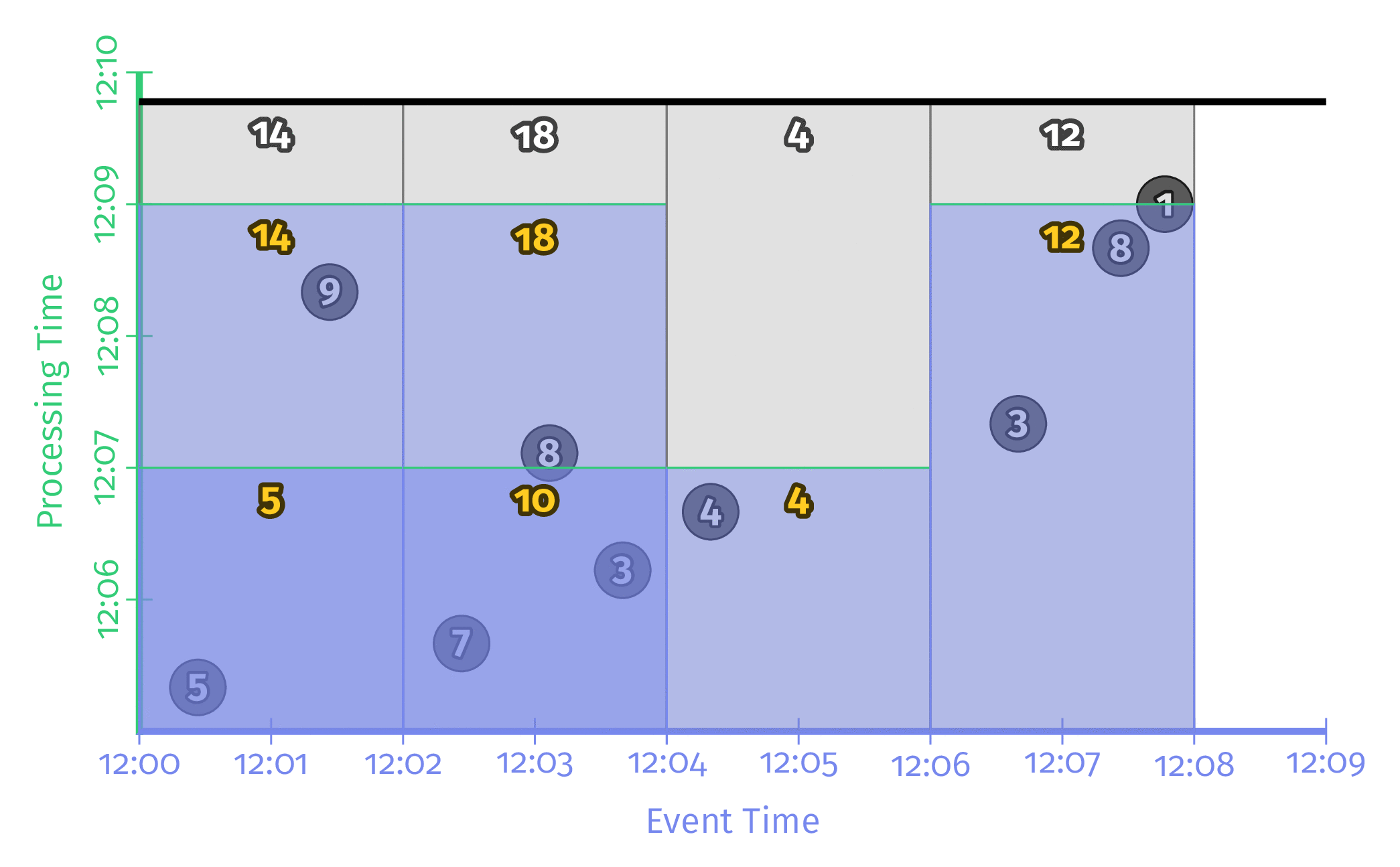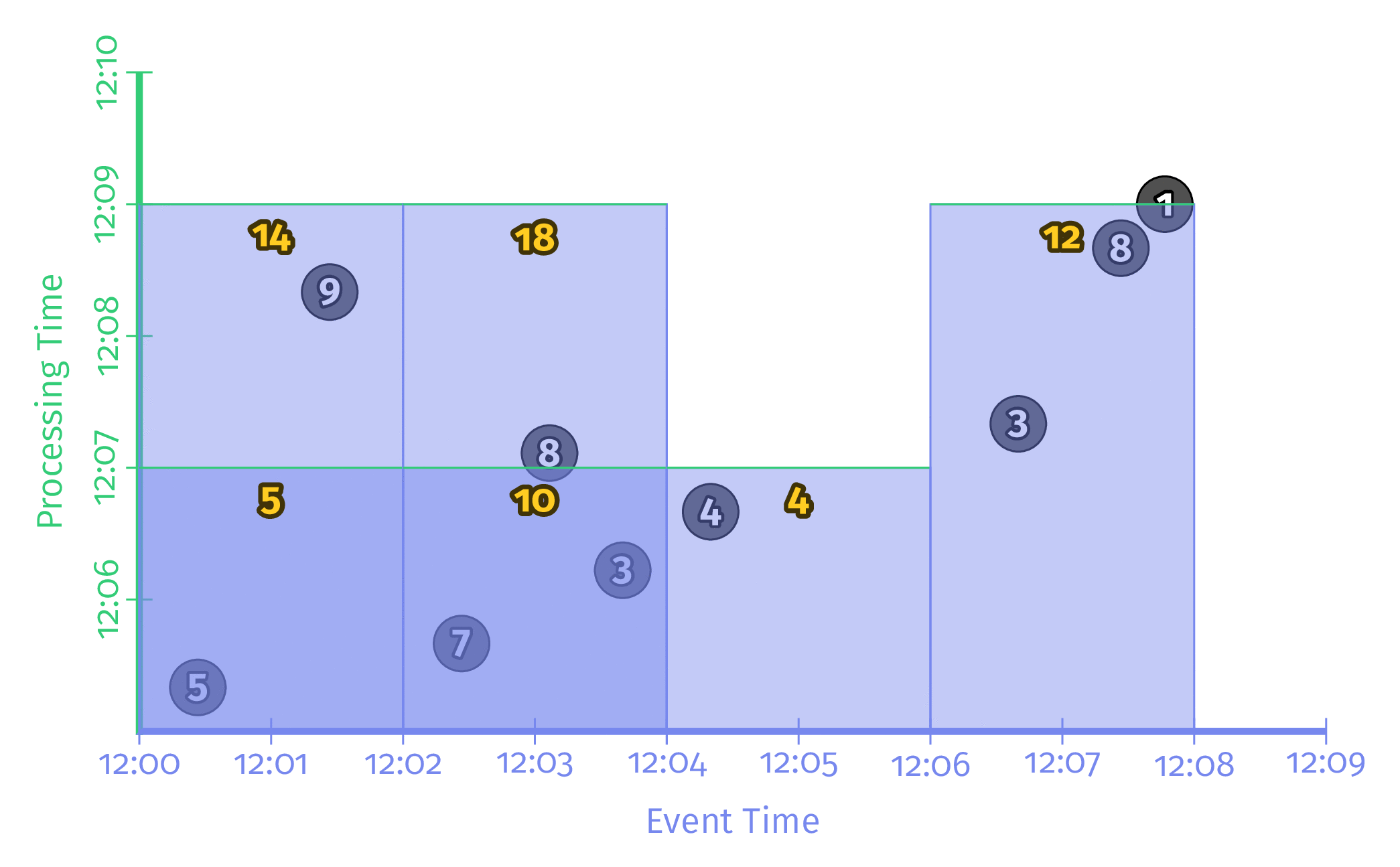
모든 Window들을 주기적으로 동시에 업데이트하는 방식이다. 대부분의 Streaming Application은 이 방식으로 동작한다. 이 방식의 단점은 모든 Window가 동일한 시점에 연산을 시작하기 때문에 해당 시점의 Workload가 매우 높고 분산되지 않는다는 점이다.
Triggering_repeatedly_with_unaligned_delays
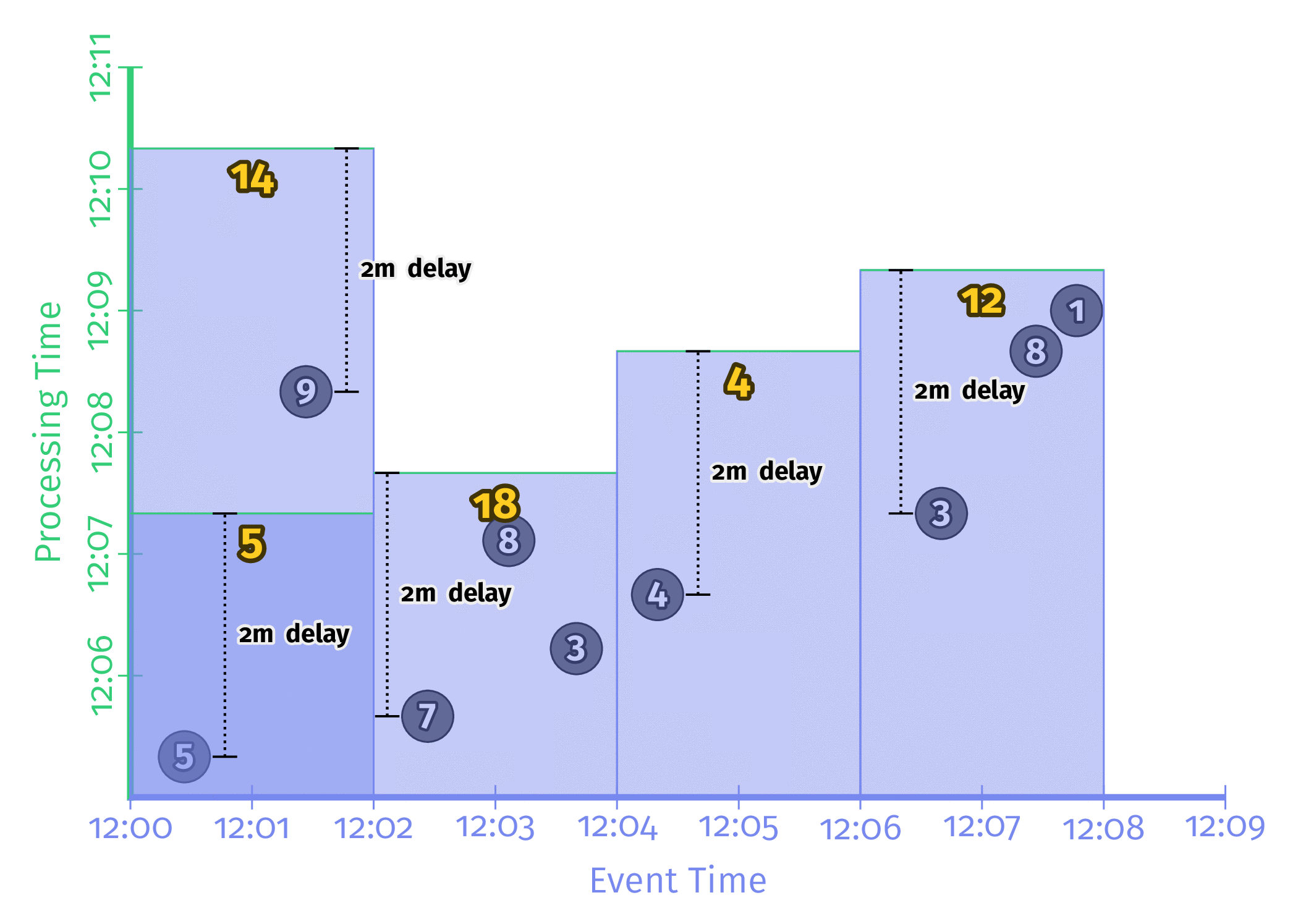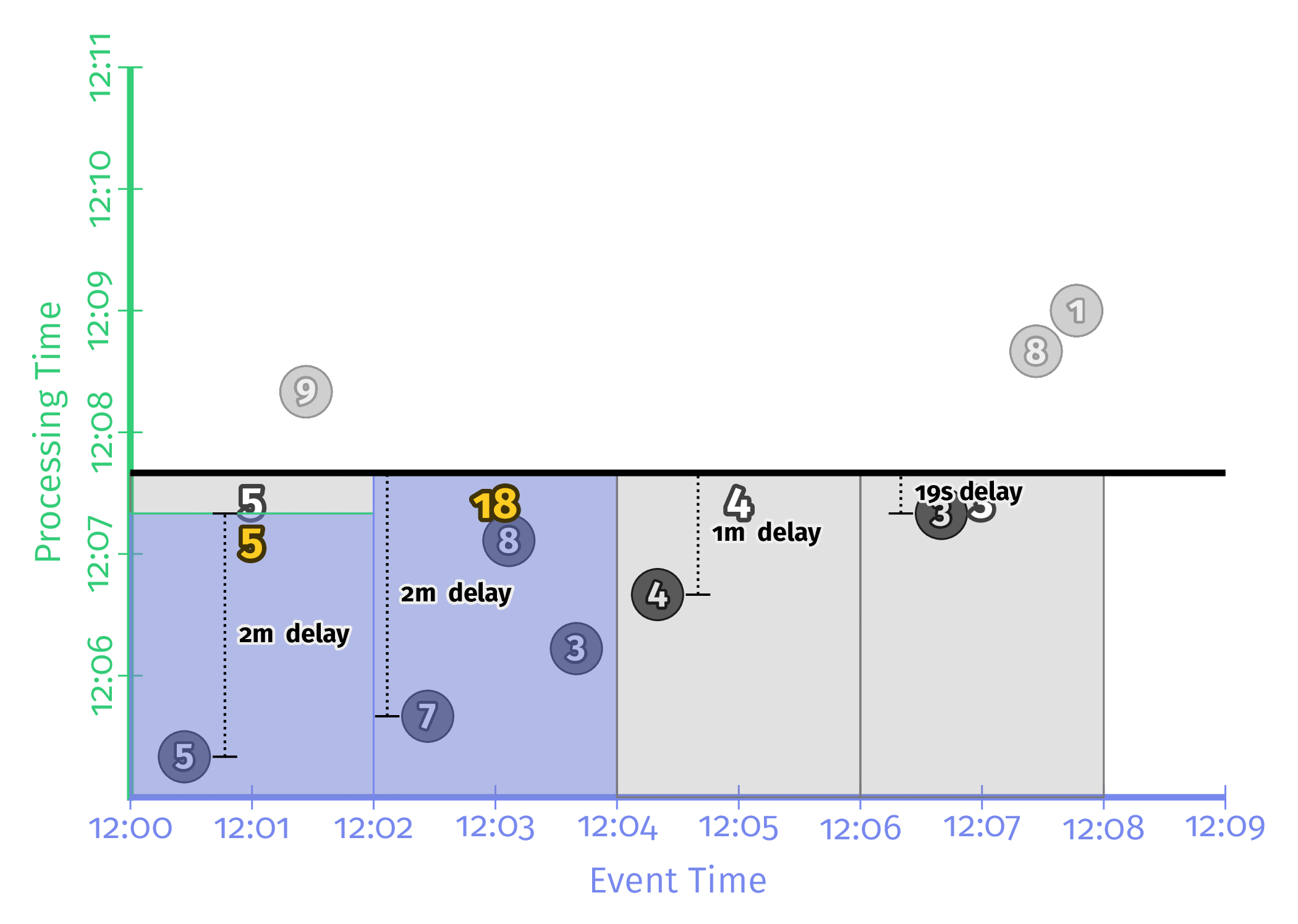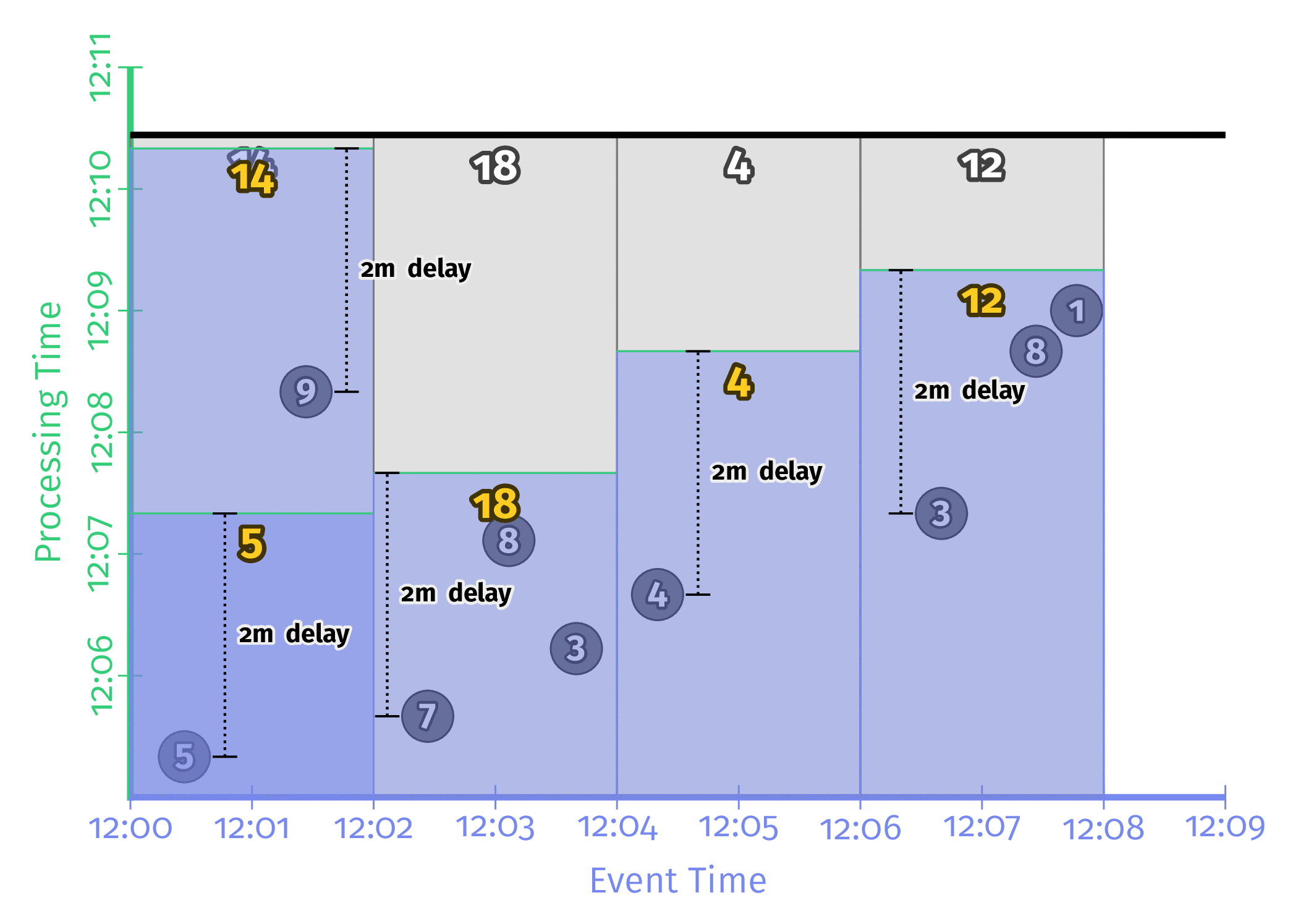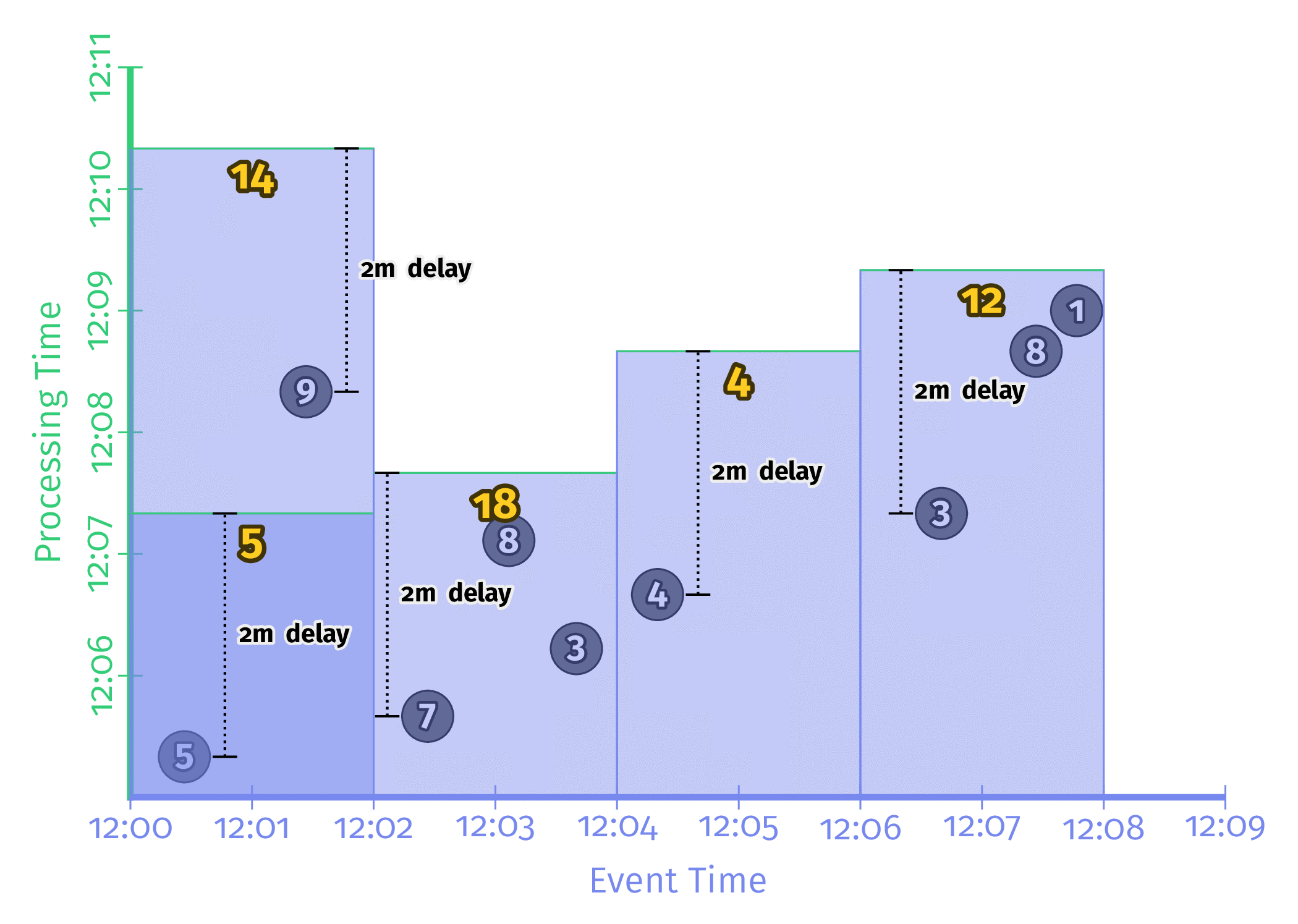
각 Window에서 처음으로 등장한 데이터의 Processing time부터 Trigger에 설정한 시간만큼 후의 데이터로 Window의 결과를 계산하는 방식이다. 모든 Window가 동시에 연산을 수행하지 않기 때문에 Workload가 분산된다는 장점이 존재한다. 다만 구현이 매우 어렵기 때문에 Google의 Dataflow나 Apache Beam에서 밖에 지원을 하지 않는 듯 하다.
결과는 (Processing time에서) 언제 집계되어 출력되는가? - Watermark
Watermark는 Event time 기준에서의 입력 데이터의 수신 완료를 결정짓는다.
데이터들의 수신은 여러 가지 이유 떄문에 늦어질 수 있다. 정말 이상적인 시스템에서라면 2019-06-29 10:10:00(Event time)에 생성된 데이터가 동일한 시각(Procesing time)에 관측되어야겠지만, 여러가지 이유로 인해 2019-06-30 23:11:00(Processing time)에 들어올 수 있다. 이와 같이 Processing time과 Event time 간에는 아무런 관계가 없고, 결과적으로 Processing time을 이용해서는 특정 시점(Event time)까지 발생한 데이터들이 모두 들어왔는지 알 수 없다.
그렇기 때문에 데이터의 수신 완료를 결정하는데는 Event time을 사용한다. Watermark는 특정 Event time X + (Watermark)에 발생한 데이터가 관측되었다면, X 이전에 발생한 데이터는 모두 수신이 완료되었다고 가정하는 것이다.
Trigger and Watermark in Spark Streaming
A 게임에는 여러 구역이 존재하고, 이런 구역들에 진입/퇴장 시 아래와 같은 로그가 발생한다.
| Event type | Event time | Zone | Character |
|---|---|---|---|
| 1(진입) | 2019-06-29 00:00:00 | A | 0 |
| 2(퇴장) | 2019-06-29 01:10:10 | A | 0 |
실시간을 특정 Zone에 남아 있는 사용자 수를 보고 싶다.
위 로그의 경우 클라이언트 로그를 사용하기 때문에 10분 간의 지연이 발생할 수 있다. 이러한 경우 Streaming Application을 작성한다면 아래와 같다.
ZoneInOutLog.scala
1
2
3
4
5
6
7
8
9
10
11
package com.leeyh0216.spark.example.log
/**
* Zone 진입/퇴장 로그 정의
*
* @param eventType 1: 진입, 2: 퇴장
* @param eventTime Event time, Format: yyyy-MM-dd HH:mm:ss
* @param zone Zone 이름
* @param character 캐릭터 UID
*/
case class ZoneInOutLog(eventType: Int, eventTime: String, zone: String, character: Int)
ConcurrentUsersInZone.scala
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
package com.leeyh0216.spark.example.application
import java.util.concurrent.TimeUnit
import com.leeyh0216.spark.example.log.ZoneInOutLog
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.execution.streaming.MemoryStream
import org.apache.spark.sql.streaming.{OutputMode, StreamingQuery, Trigger}
import org.apache.spark.sql.functions._
class ConcurrentUsersInZone(spark: SparkSession) {
implicit val sqlContext = spark.sqlContext
def preProcess(streamDF: DataFrame): DataFrame = {
streamDF
//String 타입의 eventTime을 TimeStamp 타입으로 변경
.withColumn("eventTime", to_timestamp(col("eventTime"), "yyyy-MM-dd HH:mm:ss"))
//1인 경우 진입이므로 +1, 이외의 경우 퇴장으로 간주하고 -1
.withColumn("inOutDelta", when(col("eventType") === lit(1), lit(1)).otherwise(lit(-1)))
}
def process(streamDF: DataFrame, sink: String = "memory", outputMode: OutputMode = OutputMode.Append()): StreamingQuery = {
streamDF
//마지막 Microbatch의 Max(Event Time) - 10초 까지의 데이터를 Watermark
.withWatermark("eventTime", "10 seconds")
//1분 단위로 Windowing, Zone으로도 Grouping
.groupBy(window(col("eventTime"), "1 minutes").as("window"), col("zone"))
//1분 간의 In/Out Delta 합
.agg(sum(col("inOutDelta")).as("inOutDelta"))
//Sink Format과 Output Mode 지정
.writeStream.format(sink)
.outputMode(outputMode)
.queryName("ConcurrentUsersInZone")
.option("truncate", "false")
//Watermark 작동 이후에만 결과를 갱신한다.
//1초마다 반복적으로 Repeated update trigger가 동작하여 계산하도록 합니다.
.trigger(Trigger.ProcessingTime(10, TimeUnit.SECONDS))
.start()
}
}
ConcurrentUsersInZoneTest.scala
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
package com.leeyh0216.spark.example.application
import com.leeyh0216.spark.example.log.ZoneInOutLog
import org.apache.spark.sql
import org.apache.spark.sql.functions._
import org.apache.spark.sql.execution.streaming.MemoryStream
import org.apache.spark.sql.streaming.OutputMode
import org.junit.{Assert, Test}
class ConcurrentUsersInZoneTest {
val spark = new sql.SparkSession.Builder().master("local").appName("ConcurrentUsersInZone").config("spark.driver.host", "localhost").getOrCreate()
import spark.implicits._
implicit val sqlContext = spark.sqlContext
val memoryStream = MemoryStream[ZoneInOutLog]
val app = new ConcurrentUsersInZone(spark)
@Test
def testPreProcess(): Unit = {
val df = Seq(
ZoneInOutLog(1, "2019-06-29 13:00:00", "A", 1),
ZoneInOutLog(2, "2019-06-29 14:00:00", "A", 1)
).toDF()
val answer = Seq(
(1, "2019-06-29 13:00:00", "A", 1, 1),
(2, "2019-06-29 14:00:00", "A", 1, -1)
).toDF("eventType", "eventTime", "zone", "character", "inOutDelta")
val expected = app.preProcess(df).select("eventType", "eventTime", "zone", "character", "inOutDelta")
Assert.assertEquals(0, answer.except(expected).count())
Assert.assertEquals(0, expected.except(answer).count())
}
@Test
def testProcessWithAppendMode(): Unit = {
val outputStream = app.process(app.preProcess(memoryStream.toDF()))
memoryStream.addData(
ZoneInOutLog(1, "2019-06-29 13:00:00", "A", 1),
ZoneInOutLog(2, "2019-06-29 13:00:20", "A", 1),
ZoneInOutLog(1, "2019-06-29 13:00:20", "A", 2),
ZoneInOutLog(1, "2019-06-29 13:00:45", "A", 1)
)
outputStream.processAllAvailable()
//첫번째 결과 Watermark 적용이 안되기 때문에 빈 테이블이 출력됨
Assert.assertEquals(0, spark.table("ConcurrentUsersInZone").count())
memoryStream.addData(
ZoneInOutLog(2, "2019-06-29 13:00:55", "A", 2),
ZoneInOutLog(2, "2019-06-29 13:01:11", "A", 1)
)
val answer2 = Seq(
("A", "2019-06-29 13:00:00", "2019-06-29 13:01:00", 1)
).toDF("zone", "start", "end", "inOutDelta")
.withColumn("start", to_timestamp(col("start"), "yyyy-MM-dd HH:mm:ss"))
.withColumn("end", to_timestamp(col("end"), "yyyy-MM-dd HH:mm:ss"))
outputStream.processAllAvailable()
val expected2 = spark.table("ConcurrentUsersInZone").select("zone", "window.start", "window.end", "inOutDelta")
//두번째 결과
//2번째 Stream 중 Event Time 이 가장 큰 2019-06-29 13:01:11 기준으로 Watermark 생성(2019-06-29 13:01:01)
//2번째 Stream을 포함한 이전 Stream에서 Event Time이 13:01:01보다 작은 Window들이 계산됨
Assert.assertEquals(0, answer2.except(expected2).count())
outputStream.stop()
}
@Test
def testProcessWithUpdateMode(): Unit = {
//Output Mode를 Update로 적용
val outputStream = app.process(app.preProcess(memoryStream.toDF()), outputMode = OutputMode.Update())
memoryStream.addData(
ZoneInOutLog(1, "2019-06-29 13:00:00", "A", 1),
ZoneInOutLog(2, "2019-06-29 13:00:20", "A", 1),
ZoneInOutLog(1, "2019-06-29 13:00:20", "A", 2),
ZoneInOutLog(1, "2019-06-29 13:00:45", "A", 1)
)
outputStream.processAllAvailable()
//Watermark가 적용되더라도 Update Mode이기 떄문에 연산 결과가 존재함
val answer1 = Seq(
("A", "2019-06-29 13:00:00", "2019-06-29 13:01:00", 2)
).toDF("zone", "start", "end", "inOutDelta")
.withColumn("start", to_timestamp(col("start"), "yyyy-MM-dd HH:mm:ss"))
.withColumn("end", to_timestamp(col("end"), "yyyy-MM-dd HH:mm:ss"))
val expected1 = spark.table("ConcurrentUsersInZone").select("zone", "window.start", "window.end", "inOutDelta")
Assert.assertEquals(0, answer1.except(expected1).count())
memoryStream.addData(
ZoneInOutLog(2, "2019-06-29 13:00:55", "A", 2),
ZoneInOutLog(2, "2019-06-29 13:01:11", "A", 1)
)
val answer2 = Seq(
("A", "2019-06-29 13:00:00", "2019-06-29 13:01:00", 1),
("A", "2019-06-29 13:01:00", "2019-06-29 13:02:00", -1)
).toDF("zone", "start", "end", "inOutDelta")
.withColumn("start", to_timestamp(col("start"), "yyyy-MM-dd HH:mm:ss"))
.withColumn("end", to_timestamp(col("end"), "yyyy-MM-dd HH:mm:ss"))
outputStream.processAllAvailable()
val expected2 = spark.table("ConcurrentUsersInZone").select("zone", "window.start", "window.end", "inOutDelta")
Assert.assertEquals(0, answer2.except(expected2).count())
outputStream.stop()
}
}