개요
대부분의 오픈소스 ETL 프로젝트(Spark, Flink 등)들에서는 ORC, Parquet 등의 컬럼 기반 파일 포맷의 읽기/쓰기를 지원하며, 고수준 API를 통해 간단히 특정 포맷으로의 읽기/쓰기를 수행할 수 있다.
1
2
3
4
5
-- ORC의 읽기
spark.read.orc("PATH_TO_READ").show(100, false)
-- ORC의 쓰기
df.write.orc("PATH_TO_WRITE")
현업에서 코드를 작성하는 이유는 “비즈니스 목표를 달성하기 위함” 이기 때문에, 각 오픈소스 프로젝트에서 제공하는 High Level API를 어떻게 잘 쓸 것인가(파일 정렬, Sorting, Partitioning 등)가 중요하다.
그러나 오픈소스 문서에도 High Level API의 옵션들이 어떻게 동작하는지 상세히 적혀있진 않고, 이러한 옵션에 대해 잘못 이해하고 사용할 가능성이 높다. 그렇기에 코드 레벨에서 이러한 기능을 분석하는 것이 중요하다고 생각한다.
내 경우 사용 중인 오픈소스의 ORC 관련 기능에 기여하려다보니 ORC 자체의 읽기/쓰기를 알지 못하고는 기여가 불가능했기에, 이번 기회에 ORC에 대해 깊게 알아보려 직접 ORC 읽기/쓰기 기능을 구현해보려 한다.
ORC Specification
현재 ORC Specification은 V0, V1, V2가 나와 있다.
- V0: Hive 0.11 버전에 포함되어 Release
- V1: Hive 0.12 버전과 ORC 1.x 버전으로 Release
- V2: 개발 중…
ORC는 단순히 파일 포맷이기 때문에 프레임워크에 독립적이다. 각 프레임워크는 ORC Spec 기반으로 자체 Reader/Writer를 구현하여 사용한다.
이 시리즈에서는 가장 많이 사용 중인 V1 Spec을 기반으로 읽기/쓰기 기능을 구현할 것이다.
File Tail과 Postscript
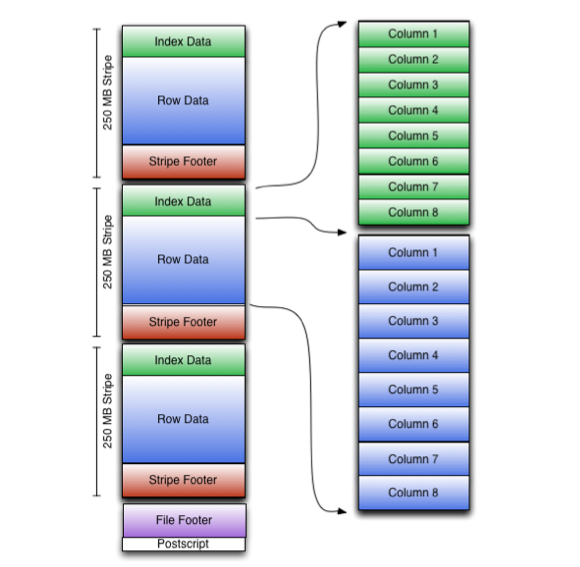
ORC 파일에 대해 기술하는 메타성 정보들은 모두 File Tail에 기록되어 있다. 이러한 메타성 정보 중 가장 먼저 읽어야 하는 정보가 Postscript이다. Postscript는 아래와 같이 프로토콜 버퍼 파일로 정의되어 있다.
1
2
3
4
5
6
7
8
message PostScript {
optional uint64 footerLength = 1;
optional CompressionKind compression = 2;
optional uint64 compressionBlockSize = 3;
repeated uint32 version = 4 [packed = true];
optional uint64 metadataLength = 5;
optional string magic = 8000;
}
footerLength: Footer의 길이compression: 압축 종류compressionBlockSize: 최대 압축 블록 크기version: 해당 파일을 읽고 쓸 수 있는 Hive의 최소 버전(List 형태로 구성되어 있음. [0, 12] -> Hive 0.12)metadataLength: 메타데이터의 길이magic: MAGIC WORD로, “ORC” 문자열이 들어가 있다.
Postscript를 읽기 위해서는 Postscript가 파일의 어떤 위치(position)에서 시작하는지 알아야 한다. Spec 문서에 다음과 같이 적혀 있는 것을 확인할 수 있다.
The final byte of the file contains the serialized length of the Postscript, which must be less than 256 bytes.
파일의 마지막 1byte에 Postscript의 길이가 저장되어 있음을 확인할 수 있다. Postscript의 크기는 256byte를 넘어갈 수 없기 때문에, 마지막 1byte만을 활용하여 길이 정보를 저장할 수 있는 것이다. 즉, Postscript의 시작 Offset = (파일 길이 - 1 - Postscript의 길이) 임을 알 수 있다.
또 한가지 중요한 점은 Postscript는 압축의 대상이 아니라는 것이다.(마지막 1byte에 길이 정보만 저장하기 때문에, 압축의 여지가 없다)
Implementation
Maven 프로젝트 기반으로 진행하며, 기본적인 Directory Structure는 생성되었다고 가정하고 진행한다.
Java ORC Proto 파일 생성
ORC 메타데이터들은 모두 Protocol Buffer 기반으로 읽기/쓰기가 가능하다. Hive에서 정의한 orc_proto.proto 파일을 기반으로 Java ORC Proto 파일을 생성해야 한다.
proto 파일을 Java 파일로 변환하기 위해서는 protoc 바이너리를 먼저 다운로드 받아야 한다. Protobuf Release 페이지에서 운영체제에 맞는 바이너리를 다운로드한다. 나의 경우 Intel 기반 맥북을 사용하고 있었기 때문에, protoc-21.12-osx-x86_64.zip을 다운로드 받았다.
압축을 푼 뒤 해당 경로(이하 $PROTOC)를 확인해보면 다음과 같은 디렉토리 구조를 확인할 수 있다.
1
2
3
4
5
6
7
bin
ㄴ protoc
include
ㄴ google
ㄴ protobuf
ㄴ ...
readme.txt
위의 $PROTOC/bin/protoc 바이너리를 이용해 proto 파일을 자바 클래스 파일로 변환할 수 있다.
우선 src/main/resource에 orc_proto.proto 파일을 복사한 뒤, 자바 패키지명을 바꿔준다. 나의 경우 생성할 파일을 com.leeyh0216.orc에 위치시킬 것이기 때문에 아래와 같이 변경하였다.
1
2
3
4
5
6
7
package orc.proto;
//원본
//option java_package = "org.apache.hadoop.hive.ql.io.orc";
//변경
option java_package = "com.leeyh0216.orc";
이후 src/main/resource 경로에서 아래 명령어를 통해 orc_proto.proto 파일을 자바 클래스파일로 변경하여 src/main/java/com/leeyh0216/orc 경로 아래에 위치시킨다.
1
> $PROTOC/bin/protoc --java_out=../java/ ./orc_proto.proto
명령어를 실행하면 src/main/java/com/leeyh0216/orc 경로에 OrcProto.java 파일이 생성된 것을 확인할 수 있다.
OrcReader 설계
ORC 파일 하나를 읽을 수 있는 클래스인 OrcReader를 만들 것이다. 이번 글에서는 PostScript 읽기까지 구현할 것이기 때문에, 대략적인 요구사항을 아래와 같이 추출해보았다.
OrcReader는 ORC 파일 1개를 읽는 책임을 가진다.OrcReader는 Lazy한 읽기를 지원한다.- 생성자에서 메타데이터를 기반으로 Stripe, Column 정보들을 초기화한다.
- 실제 Column 데이터를 읽는 시점은 Read API 호출 시점이다.
- Compression은 고려하지 않는다.
이 글에서는 우선 PostScript를 읽고 PostScript 내용을 출력하는 기능만을 구현하도록 한다.
클래스 생성 및 생성자 구현
com.leeyh0216.orc 패키지 아래에 OrcReader 클래스를 생성한다. 생성자의 인자로는 ORC 파일 경로 1개를 String 타입으로 전달받고, ORC 파일의 특정 Offset을 읽을 수 있도록 RandomAccessFile 하나를 생성한다.
1
2
3
4
5
6
7
8
9
10
11
12
package com.leeyh0216.orc;
import java.io.RandomAccessFile;
public class OrcReader {
public OrcReader(String path)
throws Exception
{
RandomAccessFile orcFile = new RandomAccessFile(path, "rw");
}
}
readByteArrayFrom 메서드 정의
일반적인 파일과 달리 OLAP 환경, 특히 Columnar Format File을 활용하는 환경에서는 파일의 모든 내용을 읽어들일 필요가 없다. 이유는 다음과 같다.
- OLTP와 다르게 OLAP에서는 전체 컬럼이 아닌 특정 컬럼만을 읽는다.
- Columnar Format은 컬럼 단위로 Block을 구성하여 저장한다.
- 필요한 컬럼을 포함하는 Block들만 읽으면 되기 때문에 I/O를 줄일 수 있다.
- Container File Format은 Block 단위로 통계 정보를 저장한다.
- 통계 정보를 기반으로 필요한 Block만을 읽어들일 수 있다.
위와 같은 이유로 Columnar, Container File Format에서는 File을 Random하게 Access하며, API 상으로도 File을 Random하게 Access할 수 있는 방법을 제공해야 한다.
readByteArrayFrom 이라는 메서드를 만들어 파일의 특정 offset에 접근하여 length 만큼의 byte 배열을 읽는 기능을 제공한다.
1
2
3
4
5
6
7
8
private byte[] readByteArrayFrom(RandomAccessFile file, long pos, int length)
throws Exception
{
file.seek(pos);
byte[] buffer = new byte[length];
file.readFully(buffer, 0, length);
return buffer;
}
위 메서드는
- ORC File의 Pointer(이하 File Pointer) 특정 위치(
pos)로 이동한다. pos~pos + length - 1까지의 데이터를 읽어byte배열에 넣는다.- 읽어들인
byte배열을 반환한다. 의 기능을 수행한다.
PostScript 읽기
Spec 문서에도 나와 있듯, PostScript의 길이는 파일 마지막 1byte에 기록되어 있다. 이 1byte를 읽어 PostScript의 길이를 알아낼 수 있다. 즉, PostScript를 읽기 위해서는
- File Pointer를
File Length - 1로 이동시킨다. - 1byte를 읽어 PostScript의 길이(
psLen)를 알아낸다. - File Pointer를
File Length - 1 - psLen로 이동시킨다. psLen만크의 데이터를 읽어 byte 배열을 얻어내고, 이를 파싱하여PostScript객체를 초기화한다. 의 과정을 수행해야 한다.
1
2
3
4
5
6
7
8
9
private OrcProto.PostScript readPostScript(RandomAccessFile file)
throws Exception
{
file.seek(file.length() - 1);
int psLen = file.readByte(); //PostScript의 길이를 얻어냄
file.seek(file.length() - 1 - psLen); //File Pointer를 PostScript 시작 위치로 이동
byte[] postScriptData = readByteArrayFrom(file, file.getFilePointer(), psLen); //PostScript 데이터 읽음
return OrcProto.PostScript.parseFrom(postScriptData); //PostScript 파싱하여 반환
}
생성자에서 읽어보자!
위의 기능을 생성자에 넣어 PostScript 내용을 출력해보도록 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
public class OrcReader {
public OrcReader(String path)
throws Exception
{
RandomAccessFile orcFile = new RandomAccessFile(path, "rw");
System.out.println(readPostScript(orcFile));
}
private byte[] readByteArrayFrom(RandomAccessFile file, long pos, int length)
throws Exception
{
file.seek(pos);
byte[] buffer = new byte[length];
file.readFully(buffer, 0, length);
return buffer;
}
private OrcProto.PostScript readPostScript(RandomAccessFile file)
throws Exception
{
file.seek(file.length() - 1);
int psLen = file.readByte(); //PostScript의 길이를 얻어냄
file.seek(file.length() - 1 - psLen); //File Pointer를 PostScript 시작 위치로 이동
byte[] postScriptData = readByteArrayFrom(file, file.getFilePointer(), psLen); //PostScript 데이터 읽음
return OrcProto.PostScript.parseFrom(postScriptData); //PostScript 파싱하여 반환
}
}
임의의 파일을 넣어 실행해보면 다음과 같은 결과가 출력됨을 확인할 수 있다.
1
2
3
4
5
6
7
footerLength: 190
compression: NONE
version: 0
version: 12
metadataLength: 102
writerVersion: 9
magic: "ORC"
회고
처음에는 ProtoBuf를 사용하지 않고도 Byte 단위의 접근으로 ORC 파일을 읽을 수 있을 줄 알았다. PostScript 길이나 Magic 등은 마지막 1byte, 3byte를 읽어들여 정상적으로 읽어졌기 때문이다. 그러나 metadataLength 등을 읽을 때 이상한 값이 들어오는 것을 확인하고는 Protobuf 없이는 정상적인 구현이 불가능함을 확인할 수 있었다.
Bottom-Up 방식으로 무언가에 접근한다는게 비생산적이고 지루하다고 생각은 드는데, 어차피 모든 오픈소스가 아래쪽으로 가면 비슷한 코드(심지어 from hive 등으로 다른 오픈소스에서 그대로 코드를 가져다 쓰는 경우도 존재)로 구성되어 있기 때문에 이번 기회를 통해 앞으로의 헛발질을 줄일 수 있다는 마음으로 임해야겠다.